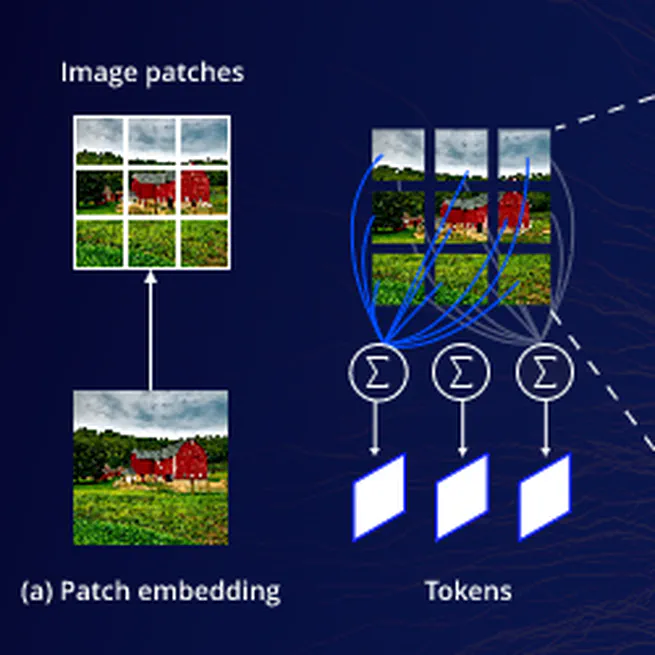
Vision Transformer (ViT) Implementation for Spoofing Detection
This comprehensive code implements a deep learning solution for spoofing detection using a Vision Transformer (ViT) architecture. The system leverages transfer learning by fine-tuning a pre-trained ViT model for binary classification, distinguishing between genuine and spoofed images in a specialized security dataset.
Jan 2, 2022